
Как мы тестировали распознавание текста с помощью GPT
Осенью 2023 года OpenAI запустили несколько новых функций ChatGPT, среди которых — возможность работать с изображениями непосредственно в чате. Способность чат-бота распознавать и обрабатывать изображения открывает много новых возможностей, одна из наиболее полезных для переводческой компании — распознавание текста с изображения. Наши специалисты верстки взялись испытать эту функцию в деле и сравнить выдачу ChatGPT и традиционных программ для оптического распознавания текста. Мы побеседовали с Костей Климентовским, разработчиком из команды верстки, и Юлей Ефимовой из Экспертного центра о том, насколько успешным оказался первый опыт применения новых функций и чем они полезны уже сейчас.
Команда верстки обрабатывает все форматы документов, изображений и текстов, чтобы переведенный в специализированной программе документ на языке перевода внешне полностью соответствовал оригиналу. Так, если требуется перевод с русского языка на иврит, для полного соответствия потребуется учесть множество нюансов: направление текста, длину строки, количество слов в переводе, расположение изображений, графиков, таблиц и подписей к ним.
Экспертный центр занимается оптимизацией лингвистических процессов (в частности, перевода) при помощи NLP (скриптов для обработки естественного языка), обучением движков машинного перевода, оценкой результатов, совершенствованием производства. Коллеги исследуют новейшие языковые технологии, например, изучают возможности чата GPT и его внедрения в работу.
Для начала расскажите, почему и для чего вы решили попробовать использовать ChatGPT для распознавания текста?
В компании ТРАКТАТ мы постоянно ищем способы оптимизации процессов, тестируем самые разные доступные технологии и инновации. Разверстка — важный этап обработки документов и файлов до их передачи в перевод, и процесс этот сам по себе трудоемкий. Добавим сюда порой плохое качество изображений, орфографические и прочие ошибки, которые приходится исправлять вручную. На подготовку некоторых текстов для дальнейшего использования уходит немало часов. При этом потенциально разверстку можно почти полностью автоматизировать. Так что мы сразу же решили проверить, насколько хорошо обновленный ChatGPT может справляться с распознаванием текстов.
Если говорить в целом, как функция распознавания ChatGPT может быть полезна в вашей работе в первую очередь?
Можно выделить две основные причины для применения новой функции GPT:
- во-первых, наша основная цель — сократить время на ручную обработку нераспознанного текста, освободив ресурс на более качественную проработку и проверку уже разверстанного материала, сложный дизайн макетов. При автоматизированном распознавании у верстальщика появится ресурс уделять больше внимания качеству готового материала — а значит, и к переводчику попадет текст с минимальным количеством ошибок. Разумеется, опечатки, орфография и пунктуация исходного текста не сильно сказываются на работе переводчика. Но бывает, что, работая в программе автоматизированного перевода, лингвист не видит оригинального текста в том формате, который прислал клиент, и может не заподозрить, что, скажем, при разверстке верстальщик пропустил ошибку в цифре. Такое уже может быть критично. Конечно, мы стараемся минимизировать этот риск за счет многоступенчатой проверки, но полностью исключить человеческий фактор невозможно. Бо́льшая автоматизация поможет предотвращать больше таких ошибок;
- во-вторых, чем меньше ручного труда задействовано, тем больше материала можно обрабатывать за тот же срок. Мы сможем увеличивать общие объемы обработанных документов, клиенты будут получать свои заказы быстрее.
На каких основных направлениях уже удалось протестировать новую функцию ChatGPT, какие гипотезы проверить?
Уже сейчас верстальщик может активно использовать чат-бот при работе с заранее разверстанным материалом, чтобы:
- определять язык текста — это особенно ценно при работе с экзотическими языками. Иногда он ошибается, но, как правило, это легко вовремя установить;
- исправлять грамматические ошибки и опечатки — к сожалению, в нашей работе это не такая редкая проблема;
- искать нужные логотипы и инфографику, когда не удается получить их от клиента в специальном формате (для этого мы используем, например, инструмент Copilot).
Эти функции помогают значительно сократить время на дообработку распознанного документа.
Кроме того, сейчас мы сосредоточились на изучении возможностей ChatGPT-4 как оптического распознавателя на растровых изображениях. Копировали изображение в чат и задавали промпт «Разверстай текст на изображении» — чат-бот выдавал его содержание.
Нам было важно понять, отвечает ли его работа нашим основным потребностям:
- на каких языках он распознает текст;
- насколько плохим может быть качество изображения;
- может ли он видеть текстовые слои, перекрывающие друг друга;
- как он работает с инфографикой и нестандартными шрифтами.
Например, оказалось очень удобно работать с двуязычным документом, составленном на китайском и английском языках: ИИ распознал оба языка. В нашей работе двуязычные документы не редкость, так что результаты таких экспериментов для нас очень ценны.


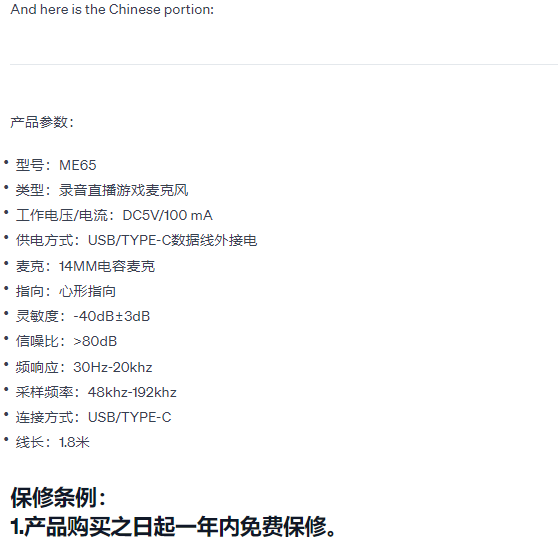
Говоря о работе с документами на разных языках, какие языки удалось охватить в начальных экспериментах? И есть ли разница в тематиках текстов, возможно, тексты на более общие темы он распознает более удачно, чем узкоспециальные материалы?
Мы попробовали поработать как со стандартным для ТРАКТАТ языком — английским, так и более экзотическими, например, фарси, и, как уже упоминалось, с китайским. Точную оценку качеству выдачи на редких языках нам еще предстоит получить от специалистов, которые ими владеют. Но как мы можем судить сами, результаты весьма хорошие.
Что касается тематик, отдельные сравнительные эксперименты мы не проводили, но и одной темой не ограничивались и разницы в качестве выдачи пока не замечали.
Какие форматы удалось протестировать? Заметили ли вы разницу в зависимости от исходного материала?
Нам удалось протестировать новую функцию на растровых изображениях — формате JPEG, доступном на момент ее выхода. Этого формата достаточно: растровая графика легко конвертируется из одного формата в другой, и при желании можно оперативно переделать изображение в нужном формате. Что касается качества, например, отсканированного документа, ChatGPT справляется и с довольно плохими исходниками, которые не под силу обычному OCR-распознавателю (программе для перевода текста с изображения в текстовые данные для их представления в текстовом редакторе — прим. автора).
Можно ли какие-то из экспериментов назвать неудачными?
Неидеальная выдача, конечно, бывает. Но нельзя какой-то из случаев назвать провальным: так или иначе ChatGPT справлялся с поставленными задачами.
Пока это были только пробные тесты; мы еще изучаем возможности ChatGPT, но первые результаты нам определенно понравились. Перспективы его применения в помощь верстальщикам очевидны.
Хочется поподробнее узнать о ваших впечатлениях от полученных результатов. Давайте начнем с минусов. Какие сейчас есть ограничения в применении ChatGPT для распознавания текста?
Основное техническое ограничение для нас на сегодня — объем исходного документа. Пока нет возможности загружать в свой промпт документы и просить распознать их целиком. Мы были вынуждены загружать отдельные скриншоты страниц, что на большом проекте отняло бы слишком много ресурсов. Поэтому пока приходится все же пользоваться привычными программами.
Как только эта проблема будет решена, вряд ли у новой функции останутся явные недостатки. Чтобы можно было массово обрабатывать большие документы, нам еще только предстоит настроить отправку изображений по API (программному интерфейсу для связи приложений между собой — прим. автора).
Новости отличные! Тогда поговорим о плюсах. Возможно, в экспериментах удалось обнаружить какие-то дополнительные полезные возможности, которые стали приятным бонусом?
Да, оказалось, что ChatGPT может не только разверстать текст в нужном формате, но и исправить ошибки. Это очень удобно.
- Можно попросить убрать текст, дублирующийся на втором языке. Нередко к нам поступают документы — будь то инструкция к медицинскому изделию или соглашение о неразглашении — в которых текст, например, на китайском полностью дублируется на английском языке, и нам нет необходимости тратить ресурс на перевод с обоих языков. Но верстальщик, как правило, не может наверняка сам определить, идентичны ли тексты. В таком случае ChatGPT может помочь определить, какой текст на втором языке нужно перевести отдельно, а какой можно просто скрыть как повторяющийся — иногда этот процесс может затянуться, если приходится обращаться за ответом к специалисту, владеющему обоими языками.


- Чат-бот может на основе общего контекста восстановить отдельные слова и словосочетания, которые не распознались из-за низкого качества отсканированного документа. При распознавании в традиционных программах приходится такие слова набирать вручную, а иногда и вовсе догадываться, что было написано. Здесь же достаточно подсветить сомнительные варианты от ИИ, чтобы в дальнейшей работе специалист просто перепроверил предлагаемые чат-ботом варианты.
- Можно задать промпт «Игнорируй текст печатей и распознай текст под ней». Далеко не на всех заказах эти печати бывают нужны. Теперь не придется убирать их вручную: чат-бот справлялся с такой задачей.
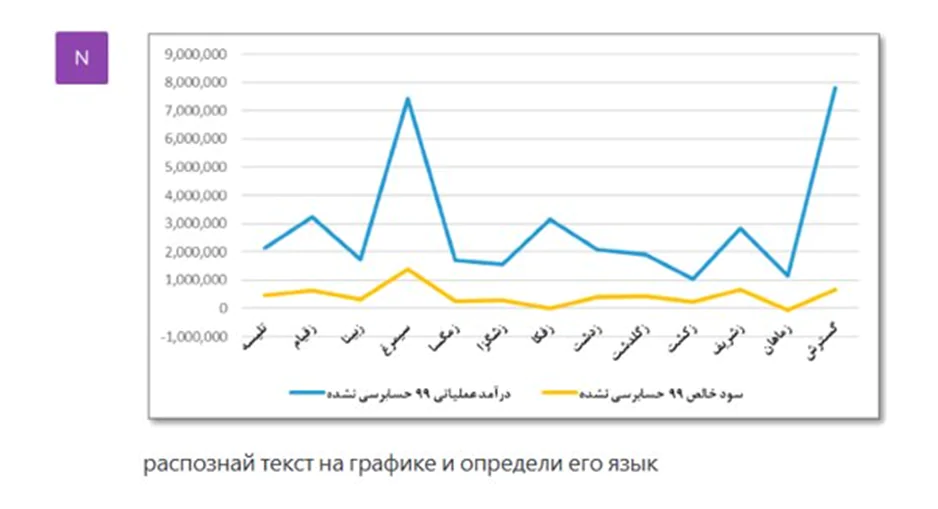
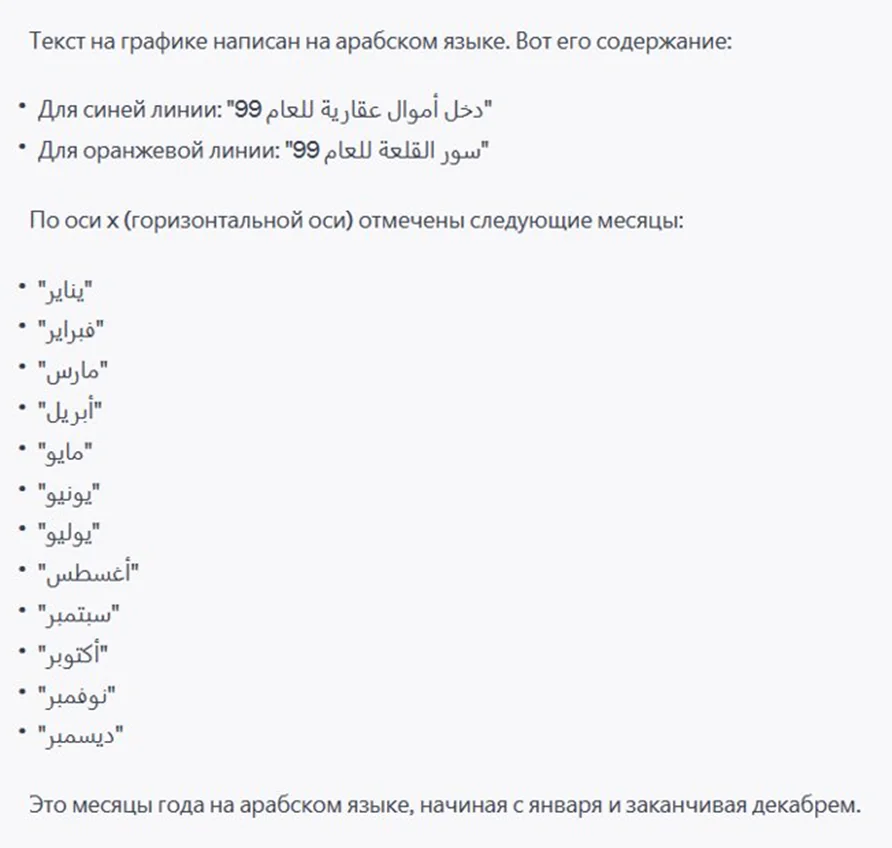
- Наконец, мы попросили ChatGPT распознать графики. И бот не просто выдал текстовое наполнение — он описывает положение каждого текстового фрагмента на нем. Это очень ценная помощь, если работаешь с языком, который тебе не известен: меньше шансов допустить серьезную ошибку.
Впечатляет! А может ли ChatGPT-4 помочь с подверсткой документов после перевода?
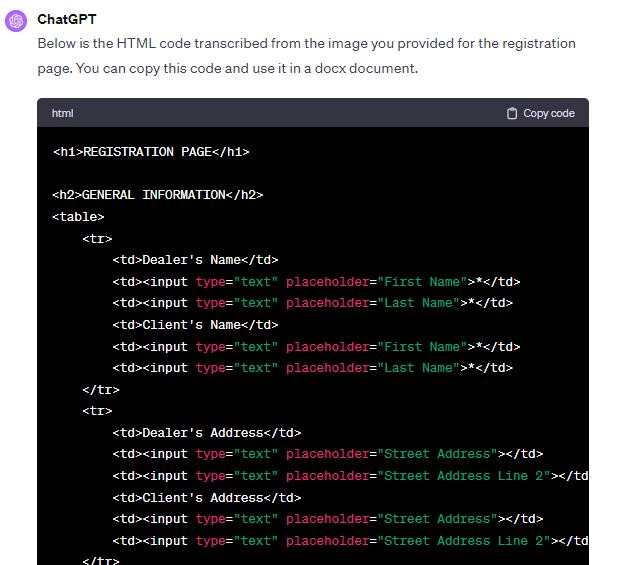
Нам показалось очень удобным, что можно попросить ChatGPT не просто выдать сплошной распознанный текст, но и сохранить его форматирование. Мы можем попросить его структурировать информацию, назначить базовые параметры — стиль и разметку. Для этого мы задали промпт «Представь текст в виде html-кода с разметкой». Далее мы копируем представленный в виде кода отформатированный текст в рабочий документ.
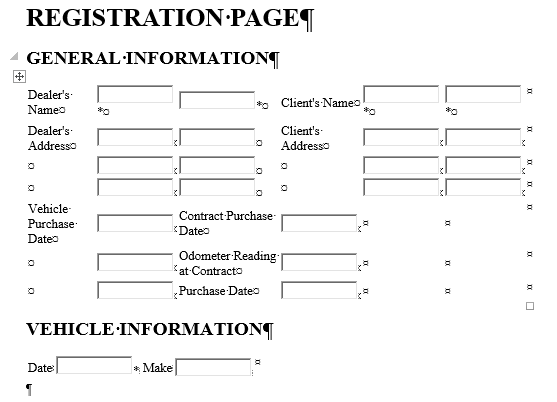
Конечно, такое оформление не будет точно соответствовать оригинальному. Но на него уже гораздо удобнее ориентироваться, ведь ты получаешь уже структурированный с помощью тегов и меток контент. Иными словами, опираясь на такую базовую разметку, можно без лишних усилий поменять описание стилей, привести форматирование в соответствие с оригиналом. В том числе удобно, когда с помощью кода можно сохранить формат таблицы и не копировать текст в каждую ячейку по отдельности.
Пример. Такая функция удобна, когда у текста сложный макет с несколькими колонками, рисунками с подписями, таблицами — порой привычный распознаватель творит невесть что, и после него приходится очень много исправлять и переделывать оформление с нуля.
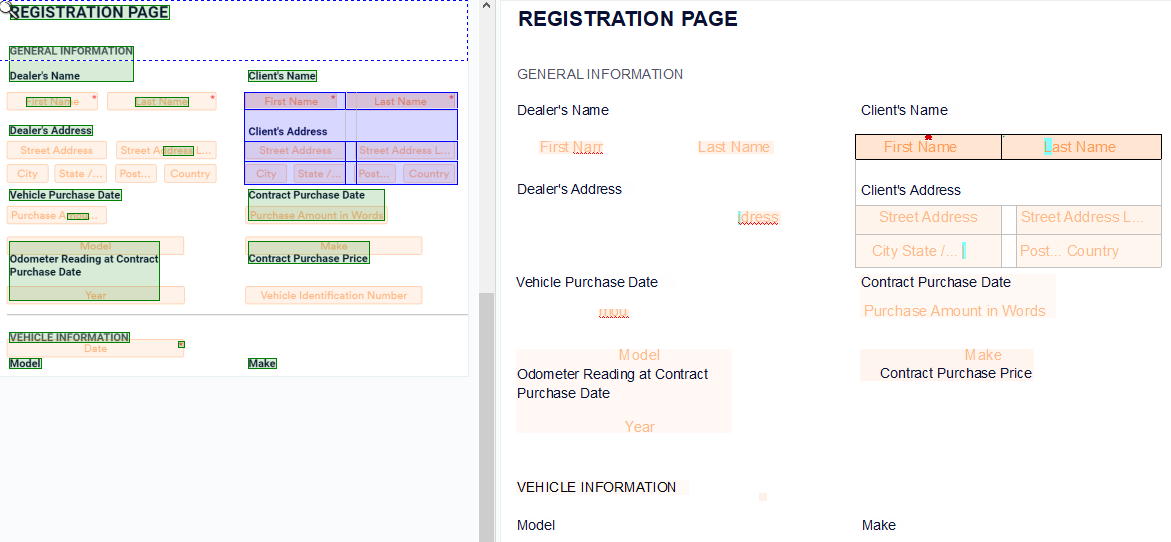
ChatGPT более разумно анализирует расположение контента и структурирует его на странице. В перспективе с его помощью мы можем получить неплохой базовый макет — с заголовками и подзаголовками, с размеченными в правильных местах рисунками и инфографикой — и уже дорабатывать его.
Другой пример — случаи, когда оригинал читается слева направо, а язык перевода (например, арабский) подразумевает расположение текста справа налево. Нам необходимо «разобрать» весь документ на составляющие и собрать его заново. Верстальщик должен полностью перевернуть содержимое макета, то есть не только текст — там меняется очень много элементов, это затратная работа.
Если с ней сможет справляться чат-бот, представьте, насколько это может ускорить процесс верстки!
При работе с разверстанным текстом в программе автоматизированного перевода случается, что в текст прокрадывается множество «мусорных» тегов из-за некорректной разверстки. Порой их бывает слишком много, при этом они не несут в себе никакой функции. Как вы считаете, форматирование текста с помощью ChatGPT поможет решить эту проблему?
Шансы очень велики, да. При распознавании традиционными программами такого «мусора» в разметке бывает немало, и подобная функция от ИИ потенциально может значительно снизить количество ошибочных и ненужных тегов.
Мы уже косвенно сравнивали сегодня ChatGPT-4 с традиционными оптическими распознавателями текста. Можете ли вы резюмировать, каковы преимущества чат-бота по сравнению с существующими программами?
Преимущества новой функции очевидны:
- ChatGPT распознает сканы более низкого качества по сравнению с традиционными программами, при необходимости восстанавливая нечитаемый текст из контекста.
- Не «сыплется» при документах на нескольких языках: спокойно распознает включения из разных языков. Традиционный распознаватель может выдать абракадабру, если в русскоязычном тексте он встретит слово на французском.
- «Видит» разные слои текста: распознает текст под большими плотными печатями. Традиционные программы обычно выдают в таких случаях бессмысленный набор символов, который приходится исправлять вручную.
Пример. Печати можно «отделить» от текста в программах вроде Photoshop, но это не самая простая задача, и этим занимаются не все сотрудники. Поэтому, как правило, в таком случае поврежденный при автоматическом распознавании текст верстальщики добирают руками, разделяя наслоившиеся фрагменты. При этом если нам попадается экзотический язык, разобраться в таких наслоениях почти невозможно ни человеку, ни традиционной OCR-программе. Тексты с печатями приходят в работу постоянно, так что подобный бонус — большое подспорье.
- ChatGPT удачно справляется не только с «чистым текстом», но и с более сложным дизайном макета, инфографикой — при этом он может подписать, к какому объекту на странице относится текст.
- Ему легче даются нестандартные дизайнерские шрифты, которые не всегда может «осилить» наша основная рабочая программа. Здесь он тоже почти не допускает ошибок.

В чем ChatGPT пока уступает традиционным программам для распознавания?
- Как мы уже говорили, в отличие от традиционных распознавателей, с ChatGPT сложно обрабатывать объемные проекты. Пока мы ограничены отсутствием нужного API и пользовательского интерфейса. На данном этапе им скорее можно пользоваться на небольших текстах или на отдельных сложных фрагментах большого документа, с которыми не удалось справиться традиционному распознавателю.
- Пока ChatGPT видит текст только как картинку, мы довольно ограничены в потенциальных функциях: как только он сможет обрабатывать PDF-документы, его возможности кратно возрастут.
- Еще одно временное ограничение — мы все еще учимся «общаться» с ботом, подбирать эффективные промпты — но мы уже активно нарабатываем свой список работающих запросов и разрабатываем скрипты под свои задачи.
В целом, интеграция возможностей искусственного интеллекта в традиционные OCR-программы не за горами, и тогда мы с вами получим что-то близкое к идеалу. Хотелось бы извлекать контент из любого формата, в том числе из «живого» PDF с гиперссылками и другими сложностями разметки, без лишних действий.
Подытоживая нашу беседу, будете ли вы продолжать тестировать ChatGPT в качестве распознавателя?
Да, без сомнений. Подобные инструменты, которые упрощают нам работу на первых этапах, не пропуская в оригинал мусор и ошибки, значительно повысят нашу производительность. Поэтому нам очень важно освоить эти новые функции от OpenAI.
Какие запросы вы уже сейчас активно применяете в работе? Облегчило ли это рутинные процессы?
Сейчас OCR-функции GPT помогают нам на отдельных языках, которых нет в поддержке нашего основного рабочего инструмента, например фарси. Конечно, работу с такими языками чат-бот заметно облегчает.
Ждем дальнейшего развития инструментария, хотя бы появления поддержки GPT OCR на базе песочницы. И надеемся, что кто-то из поставщиков необходимого нам ПО расширит свои возможности по распознаванию с технологиями, подобными GPT OCR.
Напоследок хочу попросить вас поделиться общим впечатлением от проведенных экспериментов, рассказать о дальнейших планах.
Несмотря на нынешние ограничения, общее впечатление от работы с ChatGPT положительное, мы видим большие перспективы.
- GPT выпустили новую функцию Vision, мы планируем активно ее осваивать. Для этого наш Экспертный центр будет продолжать эксперименты совместно с командой верстки: составлять работающие промпты, анализировать качество выдачи.
- Помимо этого в планах — научить бота оценивать степень сложности верстки, чтобы подбирать специалиста соответствующего уровня и корректно оценивать стоимость работы для клиента. Это возможно, если GPT станет работать с целыми документами. Например, в параметры оценки сложности макета будет входить не только визуальное расположение элементов на странице, но и необходимость повторить, к примеру, анимацию кнопки или переходов, наличие интерактивных элементов — поиск таких элементов с помощью ИИ значительно ускорит процесс.
- Не в последнюю очередь — освоение редких языков. Здесь нам понадобится привлечь в команду лингвистов, которые будут оценивать качество выдачи. Так, оценить качество распознавания фарси мы сами не беремся, поэтому пока не можем точно сказать, насколько именно этот опыт был успешен.
- Интересна возможность распознавания текстов с готовым форматированием: посмотрим, как он будет справляться с разметкой в html. Нам кажется, это перспективная функция, потенциал которой может раскрыться в работе со сложной версткой.
- В целом любая успешная автоматизация рутинных процессов поможет верстальщикам больше времени уделять более сложным и интересным задачам, дизайну макетов, проверке качества верстки. Поэтому нам не терпится продолжить осваивать все новые возможности, которые открывает искусственный интеллект.
Большое спасибо за такую познавательную и вдохновляющую беседу! Будем ждать ваших новых находок!
Примечание автора: на момент подготовки данного материала (9.01.2023) GPT еще не выпустили очередное обновление. Теперь распознавать тексты с изображений можно в отдельных плагинах. Наша команда уже начала активно изучать эти нововведения — следите за обновлениями!

